4. Technical Foundations
Work in progress
This section is under construction. This information hasn’t been reviewed or edited yet!
Introduction
Now that we’ve explored how AI evolved into its current form, let’s lift the hood and examine the engine that powers large language models (LLMs). These systems are marvels of engineering, built on a foundation of interconnected components that work together to process and generate human-like text.
What will I get out of this?
By the end of this section, you will be able to:
- Explain the process of tokenization in LLMs, including how it transforms text into computational units and its impact on model performance and cost.
- Describe the role of context windows in LLMs, comparing their evolution from early models to modern systems with extended capacities.
- Analyze how the Transformer architecture and attention mechanisms enable LLMs to process text more effectively than sequential models.
- Differentiate between various types of “memory” implementations in LLMs, including semantic, episodic, and procedural memory, and explain strategies for effective context management.
- Evaluate the importance of quality training data in LLM development, considering factors such as diversity and accuracy.
- Identify the key components of LLM learning, including weights and biases, and explain their role in pattern recognition and text generation.
How Do LLMs Actually Produce Human-Like Text?
Large language models (LLMs) like GPT and PaLM generate human-like text by leveraging advanced neural network architectures, vast training datasets, and probabilistic techniques. At their core, these models predict the next word (or token) in a sequence based on the context provided, producing coherent and contextually relevant text. Here’s a simplified breakdown of how this process works:
Tokenization:
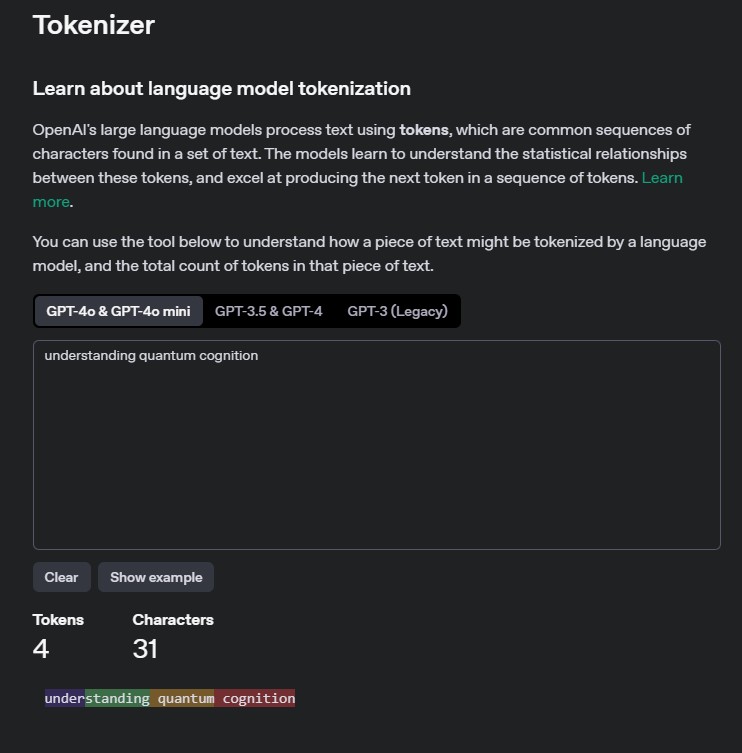
When we read a sentence, our minds don’t process it letter by letter. Instead, we recognize meaningful chunks—words, phrases, or even entire ideas. LLMs do something similar by breaking text into tokens. A token might be a single word, part of a word, or even a sequence of words depending on how common that sequence is in the model’s training data.
Concept: Tokens
Tokens are the fundamental units of text that LLMs process. They enable the model to break down language into manageable pieces for analysis and generation. Tokenization is the first step in transforming raw text into numerical representations for computation.
Remember: different tokenizers will split the text differently, and this can lead to different results!
For instance, the word ‘understanding’ might be split into ‘under’ and ‘standing,’ while other words such as ‘quantum’ or ‘cognition’ might be kept as a single token each. This varies from tokenizer to tokenizer. This flexibility allows LLMs to handle both familiar and unfamiliar text efficiently.
Contextual Understanding via Embeddings
Once tokenized, the input is transformed into embeddings—mathematical representations of tokens in a high-dimensional space.
These embeddings capture semantic relationships between words:
- Words with similar meanings (e.g., “cat” and “feline”) are placed closer together in this vector space.
- Positional encodings are added to these embeddings to help the model understand the order of words in a sentence.
Embeddings
We’ll revisit the topic of embeddings later in this chapter, but for now the important thing to remember is that embeddings form the foundation of transformer-based models like GPT, BERT, LLaMA, etc.
Think of embeddings as the “language” that AI models speak internally. Whether doing simple completion or complex retrieval tasks, the model is always working with embeddings under the hood.
Transformer Architecture
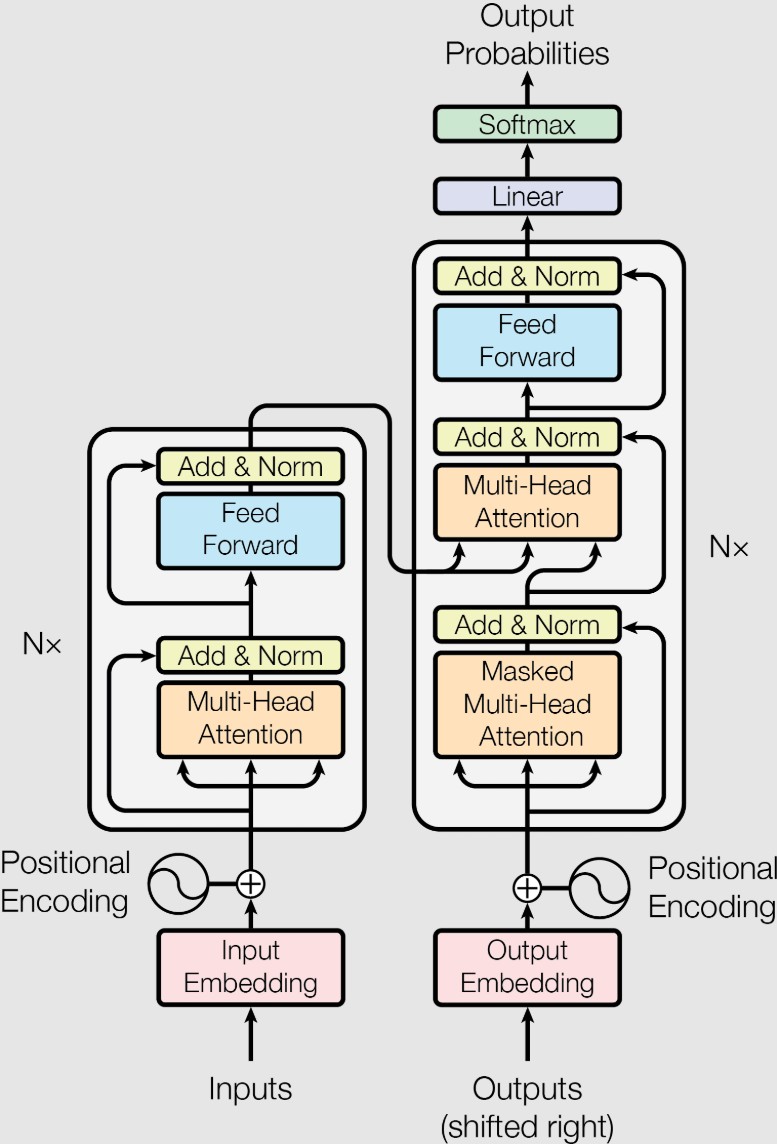
Before 2017, AI models processed text sequentially—like reading a book one word at a time. This approach struggled with long-range dependencies in language (e.g., understanding how the start of a paragraph relates to its end). The Transformer architecture changed everything by enabling models to process entire sequences simultaneously. Introduced by Google’s researchers Vaswani et al. in 2017, it revolutionized the field of natural language processing.
Imagine analyzing a painting: instead of focusing on one corner at a time, you take in the whole image while zooming in on details that matter most. Transformers use this principle to understand context across an entire input sequence.
In other words, the Transformer architecture processes input data in parallel rather than sequentially. It uses mechanisms like attention to focus on relevant parts of the input, enabling efficient handling of long-range dependencies in text.
Attention Mechanisms
Here’s an example:
“The trophy didn’t fit in the suitcase because it was too big.”
What does “it” refer to—the trophy or the suitcase? Humans rely on context to resolve this ambiguity. Attention mechanisms give LLMs a similar ability by assigning importance (or “attention”) to different parts of an input sequence.
Concept: Attention Mechanisms
Attention mechanisms allow models to weigh the relevance of different tokens within an input sequence. This capability enables nuanced understanding by focusing on contextually important information.
Transformers take this further with multi-head attention, which lets them analyze multiple aspects of context simultaneously—like examining color, texture, and composition in a painting all at once.
So in our previous “trophy” example, self-attention mechanisms help the model focus on “trophy” when interpreting “it” as the subject of the sentence.
Transformers use multiple layers of attention (multi-head attention) to analyze different aspects of context simultaneously, such as syntax, semantics, or long-range dependencies. Once the model has processed the input, it generates text token by token in an autoregressive manner.
Autoregressive Text Generation
Autoregressive generation refers to a mechanism used by LLMs in which they predict the next token in a sequence based on the previous tokens. This process follows these steps:
- The model predicts the most likely next token based on the input and previously generated tokens.
- This predicted token is added to the sequence.
- The process repeats until a stopping criterion is met, such as reaching a maximum length or encountering an end-of-sequence (EOS) token.
Concept: EOS token
An end-of-sequence token is a special marker that signals to the model that it should stop generating further tokens. It acts as a boundary for text completion, ensuring that the output ends at an appropriate point. For example, it might appear as [EOS] or </s> to mark the end of the generated text that fits the input prompt.
So, in our previous example, the model might predict the next token to be “I” and add it to the sequence, and so on. In our example, the model might generate the following text:
“The trophy didn’t fit in the suitcase because it was too big. I’m going to have to buy a new suitcase.”
Context Windows
A model’s context window represents its ability to “remember” and process information. For instance, a model with a 4,000-token context window can work with roughly 3,000 words of text at once. This capacity affects everything from document analysis to conversation memory.
Concept: Context Windows
Context windows define the maximum amount of input text an LLM can process at once, imposing practical limits on long-form tasks.
Modern models have pushed these boundaries significantly:
- Early models managed only 512 tokens
- Mid-generation models reached 2,048-4,096 tokens
- Modern models such as Google’s Gemini boast more than 2 million token context windows
For perspective, each token represents approximately 4 characters or about 0.75 words in English. This means Gemini 1.5 Pro can theoretically process around 1.5 million words at once - equivalent to multiple novels in a single context window.
Note
This is an important concept to understand, as it is not only the basis of how LLMs work, but also usually the basis on how LLM usage is billed. On API usage from a provider, you usually will pay for the number of tokens processed. Normally input tokens are cheaper, and output tokens are more expensive.
Memory
Memory in LLMs refers to how these models maintain and manage information during conversations or interactions. However, it’s crucial to understand that this “memory” is fundamentally different from human memory.
LLMs are Stateless
LLMs are inherently stateless - each inference (generation of text) is completely independent. They have no built-in ability to remember previous interactions or maintain ongoing conversations. What we call “memory” in LLMs is actually implemented through external systems and careful management of inputs.
Types of Memory Implementation
-
Semantic Memory (Facts & Knowledge):
- Stores specific facts and information
- Example: User preferences, biographical details, or domain-specific knowledge
- Implementation methods:
- Profile approach: Single, updated document with user information
- Collection approach: Multiple documents with specific pieces of information
-
Episodic Memory (Experiences & Interactions):
- Records specific interactions or conversations
- Example: Previous troubleshooting steps in a support conversation
- Implementation methods:
- Conversation history management
- Few-shot example storage and retrieval
-
Procedural Memory (Instructions & Rules):
- Defines how the model should behave
- Example: System prompts, formatting rules, response guidelines
- Implementation methods:
- System prompts
- Instruction fine-tuning
- Dynamic prompt adjustment
Memory Storage Methods
Remember that LLMs are stateless, so the memory ultimately is an addendum to the prompt. It is an external mechanism that is built to dynamically change the prompt based on the conversation history and the information the LLM may need to know at any one time.
There are several ways to implement memory, but they all essentially boil down to the same thing:
- Vector Databases:
- Store text as numerical representations
- Enable semantic search
- Efficient retrieval of relevant information
Concept: Vector Databases
Vector databases store text as numerical representations and enable semantic search, allowing for efficient retrieval of relevant information. We’ll cover them to more detail in the Vector Operations and Embeddings section below.
-
Traditional Databases:
- Store structured data
- Quick access to specific facts
- Good for user profiles and preferences
-
Document Collections:
- Store raw text and documents
- Flexible and easy to update
- Useful for maintaining conversation history
Here’s how a chatbot might implement memory. It is not exhaustive, but it shows that there are different use cases for memory beyond keeping track of the conversation history, each requiring different implementation strategies:
1. Store user preference: "Prefers technical explanations"
2. Save conversation history in chunks
3. Before each response:
- Retrieve relevant preferences
- Load recent conversation context
- Generate response considering both
4. After response:
- Update conversation history
- Extract and store new learned informationMemory Management Strategies
-
Summarization:
- Condense long conversations into key points
- Example: “Previously discussed: user’s project requirements, budget constraints, and timeline”
- Helps maintain context while saving tokens
-
Selective Retention:
- Keep important information, discard less relevant
- Prioritize based on:
- Recency (newer messages)
- Relevance to current topic
- Explicit user instructions
-
Memory Augmentation:
- External vector databases
- Knowledge bases
- API integrations
- Allows “remembering” beyond context limits
Context Management
Memory management is a crucial aspect of LLMs, and one of the greatest challenges in building with them. It is how the model is able to maintain a coherent conversation with the user. Effective context management is crucial for maintaining coherent conversations. It can be achieved through a combination of techniques:
- Keep track of token usage
- Use summarization for long conversations
- Prioritize recent and relevant information
Think about it this way…
Imagine trying to remember a phone number someone is telling you: Miller’s Law tells us that we can probably hold about 7 digits in our short-term memory easily. If they keep adding more numbers (like an extension, country code, etc.), you’ll start dropping the earlier digits unless you write them down or group them meaningfully. LLMs work similarly with their context window - they can only “remember” a certain amount of information at once.
For example, if you’re in a long conversation about planning a party, you might summarize earlier details like “We decided on Saturday at 7 PM” while keeping recent discussion about food choices fresh in your memory. This is exactly how context management works - keeping the most relevant information while condensing older details to make room for new ones, or removing details that are no longer relevant.
Learning and Training
Understanding how LLMs manage context leads us to a deeper question: how do these models learn to understand and process information in the first place? Just as we humans learn to manage information through experience and training, AI models must be trained to recognize patterns and relationships in data. Let’s explore how this learning process works.
How Does the AI Learn These Relationships?
To understand how AI models learn, let’s use a simple analogy: imagine teaching a child to recognize animals.
Weights: Think of weights as the “strength” of connections in the AI’s “brain”:
- Just as a child learns that “having fur” is strongly connected to “being a mammal”
- The AI learns that certain patterns in text are strongly connected to certain meanings
- These connections are represented by numbers (weights) that the AI adjusts as it learns
Think of it This Way…
A child learning that “meows” is strongly connected to “cats” but weakly connected to “dogs” (because both are sounds animals make). The strength of these connections represents the weights in an AI model 🐱🐶
Biases: These are like the AI’s default assumptions or starting points:
- They help the model make better predictions based on common patterns
- For example, after “The sun is…” the model might default to words like “bright” or “hot”
- However, biases can also reflect problematic assumptions from training data
Important Note About Bias
Just like humans can develop biases from their environment, AI models can learn biases from their training data. For example, they might associate certain jobs with specific genders or favor certain cultural perspectives. Addressing these biases is an important part of AI development.
The Importance of Quality Data
Just as a child learns better from good educational materials, AI models need high-quality training data to perform well. Here’s what makes data “good”:
-
Diversity: The data should include:
- Different writing styles (formal, casual, technical)
- Various topics and perspectives
- Multiple languages and dialects
-
Quality: Like choosing good textbooks for students:
- Accurate and reliable information
- Well-written and clear content
- Free from errors and inappropriate material
Think of it This Way…
Imagine learning a new language only from news articles 📰 You might become great at understanding formal writing but struggle with everyday conversations, slang, or technical terminology. AI models face the same challenge - they need exposure to many different types of language use to develop well-rounded understanding.
Quality and Challenges
Like any technology, the quality of an AI model depends on how well it’s built and trained. The weights and biases it learns, combined with the quality of its training data, determine how well it can understand and generate text.
Looking Ahead
In later chapters, we’ll explore more deeply how AI models are trained, how they learn these weights and biases, and how we can ensure they learn from high-quality, unbiased data.
Quiz
Let’s test your understanding!
Want to test your understanding of the technical foundations that power Large Language Models? This quiz focuses on conceptual comprehension rather than memorizing facts.
Coming up next
Now that we understand how LLMs represent and process information, we’re ready to explore how they’re actually used in real-world applications. In the next section, we’ll look at practical examples of AI systems and their impact across different industries.