1. Introduction to AI and LLMs
Work in progress
This section is under construction. This information hasn’t been reviewed or edited yet!
TL;DR
Too long to read? Prefer to listen to this section? We got you covered! This is a version of this section as an audio postcast produced using Google’s NotebookLM.
Using AI to teach you AI, how meta!
Alternatively, if you feel like you know this already, try your hand at the optional quiz below and see how you do. Or you can just skip to the next section. We won’t judge you!
Introduction
Welcome the first step on the road to understand Generative AI and LLMs! This section will provide a technical foundation for understanding how AI has evolved into today’s powerful Large Language Models (LLMs), focusing on the architectural breakthroughs and implementation patterns that enable systems like GPT, Claude, DeepSeek, Llama, and Gemini.
In 1950, Alan Turing posed a profound question: “Can machines think?” Today, we’re not just contemplating this question—we’re building systems that can process natural language, generate code, and solve complex problems through advanced neural architectures and training methodologies.
What will I get out of this?
By the end of this section, you will be able to:
- Explain the evolution of AI from rule-based systems to machine learning, deep learning, and Transformer-based architectures, emphasizing key milestones like neural networks and Generative AI.
- Describe the foundational principles behind neural networks and Transformer models, focusing on their relevance in natural language processing and their role in enabling LLMs.
- Identify the capabilities and limitations of Large Language Models (LLMs), including their applications in industries such as healthcare, education, cybersecurity, and creative fields.
- Understand the concept of prompts and their importance in guiding LLM outputs, including examples of effective and ineffective prompts.
- Recognize AI vulnerabilities, such as biases, adversarial inputs, data poisoning, and hallucinations, and explain their implications for security and ethical use.
- Differentiate between AI errors (e.g., hallucinations vs. outdated data) and describe strategies for mitigating these issues in practical applications.
- Evaluate societal impacts of LLMs, discussing their transformative potential across industries while critically assessing ethical concerns like bias amplification, automation risks, and regulation challenges.
The Evolution of AI: A Technical Perspective
From Rules to Learning
Early AI systems relied on rigid, rule-based programming. For example, teaching a computer to recognize a cat required painstakingly writing rules like “If it has pointy ears and whiskers, it’s probably a cat.” However, this approach quickly fell short in handling real-world complexity. Intelligence isn’t about following static rules—it’s about learning and adapting.
Consider an early AI system designed to play chess. It would follow a set of predefined rules for each possible move. However, it couldn’t adapt to new strategies or learn from its mistakes, making it less effective against skilled human players.
The Machine Learning Breakthrough
The turning point came when researchers shifted from programming rules to teaching machines how to learn. Instead of manually coding every rule, they fed computers massive datasets—like millions of cat images—and let algorithms discover patterns on their own. This marked the birth of machine learning.
Instead of writing rules to identify spam emails, machine learning algorithms can be trained on a large dataset of emails labeled as spam or not spam, learning to identify spam based on patterns in the data.
The Neural Revolution
Deep learning took this further by mimicking how human brains process information through layers of interconnected nodes called neurons. Each layer processes specific features—like edges in an image—before passing information to deeper layers for more abstract understanding.
Voice assistants like Siri and Alexa use deep learning to understand and respond to spoken language, even with different accents and speech patterns.
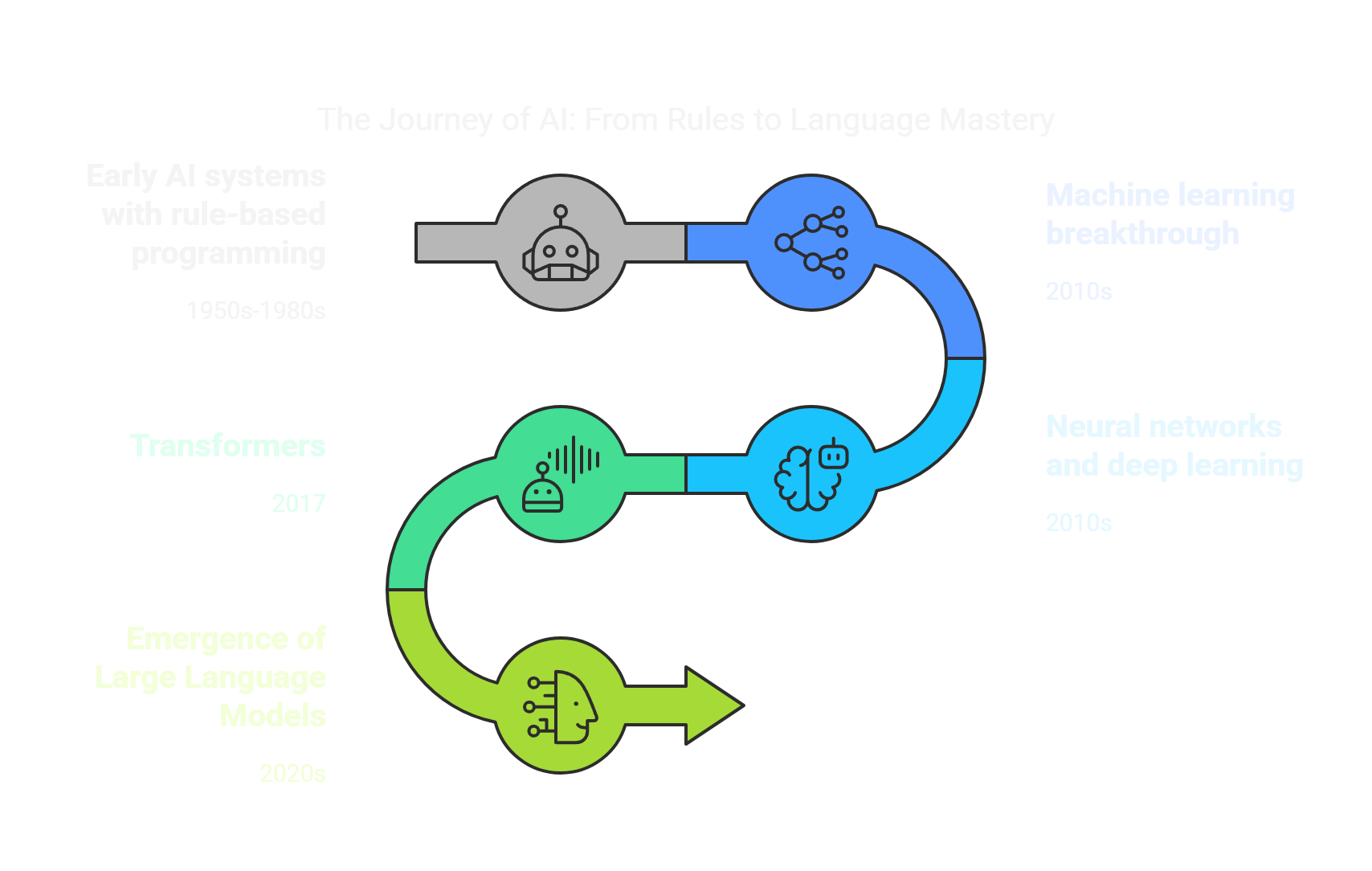
A Language Leap: Transformers
In 2017, the introduction of the Transformer architecture revolutionized natural language processing. Transformers excel at understanding context—a critical skill for language comprehension. For instance, when reading “The bank is closed,” a Transformer can discern whether “bank” refers to a financial institution or a riverbank based on surrounding words.
GPT-4o and Claude 3.5 Sonnet, both Transformer-based models, can generate coherent and contextually relevant text, such as writing essays, answering questions, or even creating poetry.
This innovation introduced a new paradigm called Generative AI (GenAI) - AI systems designed to create new content such as text, images, audio, or code based on patterns learned during training. Unlike traditional AI that focused on classification or prediction tasks, GenAI can produce original outputs that weren’t explicitly programmed.
This innovation paved the way for Large Language Models (LLMs) such as GPT, Claude, and Gemini. These models don’t just process text; they understand concepts, make connections, and generate creative outputs.
Capabilities and Limitations
Modern LLMs can assist in various tasks, including:
- Writing essays or code
- Translating languages
- Summarizing reports
- Automating cybersecurity workflows such as analyzing threat reports or detecting phishing attempts
Understanding Prompts: The Basic Building Block
At their core, LLMs work by responding to “prompts” - text inputs that tell the model what we want it to do. Think of a prompt as a conversation starter or instruction that guides the AI’s response. The way we phrase these prompts significantly impacts the quality and usefulness of the AI’s response. For example:
Prompt: "Explain quantum computing like I'm 10 years old"
Response: The model will attempt to simplify this complex topicPrompt: "Analyze this code for security vulnerabilities: [code snippet]"
Response: The model will examine the code and highlight potential security issuesA well-structured prompt typically includes:
- Clear instructions about what you want
- Relevant context or background information
- Any specific requirements for the format or style of the response
This careful crafting of prompts has evolved into its own discipline known as Prompt Engineering - both an art and a science that involves creating effective instructions for AI models. A skilled prompt engineer knows how to break down complex tasks into clear directives, provide the right context, and set appropriate constraints that guide the model toward producing accurate and useful responses. They can anticipate potential misunderstandings and know when to include specific examples or formatting requirements. As organizations increasingly rely on AI interactions, this skill has become crucial for maximizing effectiveness while minimizing errors and hallucinations.
Think of it This Way…
We’ll talk about Prompts and Prompt Engineering in more detail in another section ahead, but for now think of Prompts as instructions given to a very capable but very literal-minded assistant. The clearer and more specific your request, the better the response you’ll receive.
Limitations and Vulnerabilities
However, these models are not infallible. While they excel at generating human-like text, they also have critical limitations and vulnerabilities that must be understood for safe, responsible and effective use. We’ll cover these in more extensive detail later in this course, but here is a quick overview:
Biases
Models may reflect biases present in their training data, leading to unfair or inappropriate outputs.
Vulnerabilities to Threats
- Prompt Injection: Attackers can manipulate model outputs by crafting malicious inputs.
- Data Poisoning: Models trained on compromised datasets may inherit harmful behaviors or inaccuracies.
- Adversarial Inputs: Carefully designed inputs can cause models to behave unpredictably or generate harmful responses.
These vulnerabilities highlight the importance of understanding not just what LLMs can do, but also where they fall short—and how they can be exploited. We’ll explore these threats in detail in Chapter 2, where we focus on LLM vulnerabilities and again in Chapter 3 as we explore ways to mitigate risks.
Hallucinations and erroneous outputs
Models can generate content that appears convincing but has no basis in reality or their training data, and state it in a confident manner. This can be a serious issue in high-stakes applications, such as in agentic workflows where the model is used to make decisions and take actions, beyond just providing information.
Security Implications
It is key to be always aware of these limitations, since they are not just technical challenges; they also define the attack surface that cybersecurity solutions must look out for. From biased training data to adversarial inputs, understanding these foundational risks is essential for building secure AI systems.
Understanding AI Hallucinations
Hallucinations in AI represent a complex challenge that goes beyond simple mistakes or errors. They occur when an AI system generates content that appears convincing but has no basis in reality or its training data.
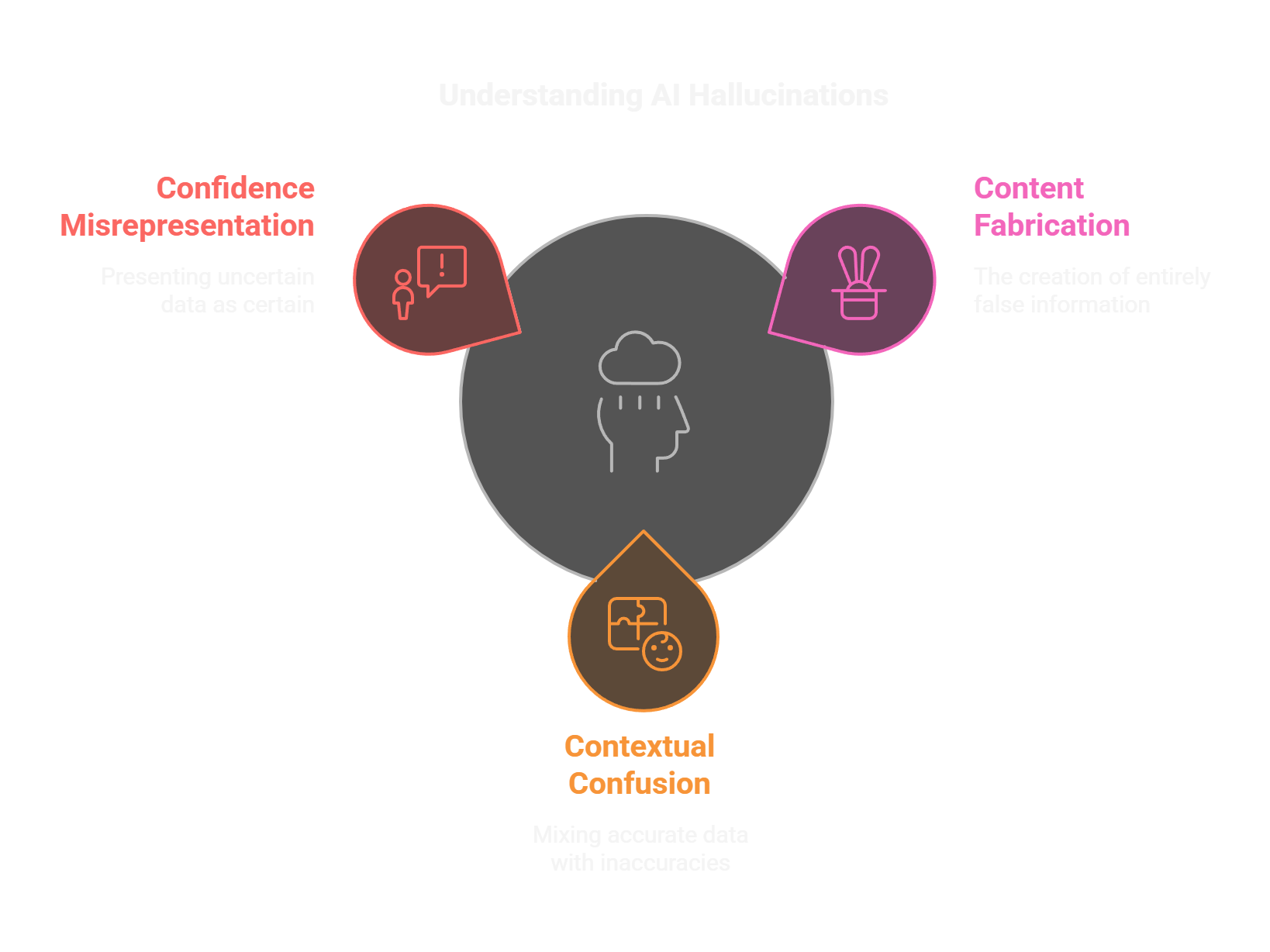
Types of Hallucinations
-
Content Fabrication:
- Complete invention of facts, figures, or narratives
- Generation of non-existent sources or references
- Creation of false relationships between real entities
-
Contextual Confusion:
- Mixing accurate information with false details
- Temporal inconsistencies (mixing up timelines)
- Inappropriate transfer of attributes between subjects
-
Confidence Misrepresentation:
- Presenting speculative information as factual
- Maintaining false certainty despite contradictory evidence
- Generating precise but incorrect details
Important Distinction!
While it is a catchy term that is being used ubiquitously, not every AI error is a hallucination! There are other types of errors that can emerge from LLM use that are not hallucinations. The key differences include:
| True Hallucinations | Other AI Errors |
|---|---|
| Generated content has no basis in training data | Outdated information from training data |
| Cannot be traced to any legitimate source | Misunderstandings of context or instructions |
| Often highly specific and detailed | Processing or formatting mistakes |
Why This Distinction Matters
Understanding the difference helps choose the right solution:
- Hallucinations: Addressed through temperature settings, better prompting, or external verification
- Training Data Errors: Fixed by updating or cleaning the training dataset
- Ambiguous Outputs: Improved through better prompt engineering
In short, not all AI errors are hallucinations, and mitigation strategies vary by error type.
What impact are LLMs having on industries and modern society?
Imagine a world where your doctor consults not just their years of medical training but also an AI assistant that has analyzed millions of medical studies in seconds. Picture a classroom where every student has access to a personalized tutor who adapts to their learning pace, or a newsroom where journalists collaborate with AI to fact-check stories in real time. These scenarios are no longer distant dreams—they’re becoming reality, thanks to the rapid adoption of Large Language Models (LLMs).
Transforming Industries
Across industries, LLMs are acting as catalysts for innovation. In healthcare, for instance, these models are revolutionizing diagnostics. A radiologist might use an AI system to flag anomalies in X-rays or MRIs, speeding up diagnosis and reducing human error. But this isn’t without risks—what happens if the model hallucinates a condition that doesn’t exist? The stakes are high, and so is the potential.
Education
Education is another domain undergoing seismic shifts. Teachers now have tools that can summarize complex topics, generate lesson plans, or even provide instant feedback on student essays. Yet, there’s an ongoing debate: Will students become overly reliant on AI, losing the ability to think critically? Educators must strike a balance between leveraging these tools and fostering independent thought.
Creative Industries
In the creative industries, LLMs are both a boon and a challenge. They can draft marketing copy, write scripts, or even compose music. However, questions about originality and intellectual property loom large. Is a song co-written by an AI truly creative? And who owns the rights to it—the user or the developer of the model?
Cybersecurity
Even cybersecurity professionals are finding new allies in LLMs. These models can analyze threat reports or detect phishing attempts at scale. But ironically, they also introduce new vulnerabilities: adversarial inputs can manipulate outputs, while attackers might exploit models to craft more convincing phishing emails or craft polymorphic malware quickly and easily.
Shaping Society
Beyond individual industries, LLMs are reshaping societal structures in profound ways. Automation is one of the most contentious issues. As repetitive tasks are handed over to AI—whether it’s customer service chatbots or data entry systems—millions of jobs could be displaced. Yet history shows that technological revolutions often create new opportunities. The rise of AI has already spurred demand for roles in model development, ethical oversight, and AI governance.
Bias amplification
Bias amplification is another critical issue. LLMs trained on biased datasets risk perpetuating societal inequalities. For example, an AI used in hiring could favor certain demographics if its training data reflects historical biases. The challenge lies in designing systems that not only reflect but also improve upon human fairness.
Ethical concerns
Ethical concerns extend beyond bias. Hallucinations—a hallmark limitation of LLMs—pose risks in high-stakes applications like legal advice or medical recommendations. Imagine an AI confidently citing non-existent laws or recommending harmful treatments; the consequences could be catastrophic.
Regulation and Public Perception
Regulation is emerging as a key area of focus. Governments worldwide are grappling with how to govern these powerful tools without stifling innovation. The European Union’s AI Act is one example of proactive legislation aimed at classifying AI systems by risk level and imposing safeguards accordingly.
The public’s perception of AI oscillates between awe and fear. On one hand, there’s excitement about its potential to solve humanity’s biggest challenges—from climate modeling to disease eradication. On the other hand, misconceptions about “sentient” machines fuel dystopian fears.
Transparency will be crucial in building trust. Users need to understand not just what these models can do but also their limitations—why they sometimes hallucinate or fail spectacularly at tasks humans find trivial.
The Road Ahead
As we stand at this crossroads, one thing is clear: LLMs are not just tools; they are mirrors reflecting our own ingenuity and flaws. Their impact will depend on how responsibly we wield them—balancing innovation with ethics, efficiency with fairness, and automation with humanity.
Quiz
Let’s see how much you’ve learned!
Want to test your knowledge of the basic evolution of AI from rule-based systems to machine learning and deep learning? Give it a try!
(Optional) Practical Activity
This course assumes that you have had some exposure to AI and LLMs, but if you are completely new to this technology, we recommend you go through this activity.
Coming up next
Now that we’ve explored how AI has evolved into today’s powerful LLMs, it’s time to look at the industry as it is right now. The big players and their models, their similarities, differences and respective strengths.